新闻资讯 你的位置:开云(中国)Kaiyun·官方网站 登录入口 > 新闻资讯 > 开yun体育网如今他们仨又在Anthropic汇合了……闲聊休说-开云(中国)Kaiyun·官方网站 登录入口
开yun体育网如今他们仨又在Anthropic汇合了……闲聊休说-开云(中国)Kaiyun·官方网站 登录入口
发布日期:2025-05-20 13:51 点击次数:83
梦晨 西风 发自 凹非寺量子位 | 公众号 QbitAI
之前引导OpenAI安全团队的北大学友翁荔(Lilian Weng),下野后第一个动作来了。
虽然是发~博~客。
前脚刚发出来,后脚就被大伙儿皆刷刷码住,评述区一堆东谈主列队加待读清单。
还有不少OpenAI前共事转发推选。
此次的博客一如既往万字干货,妥妥一篇筹划综述,翁荔本东谈主直言写起来辞谢易。
主题围绕强化学习中奖励黑客(Reward Hacking)问题伸开,即Agent期骗奖励函数或环境中的轻视来获取高奖励,而并未真确学习到预期行动。
她强调奖励黑客行动在大模子的RLHF覆按中的潜在影响,并命令更多筹划关注交融和善解这一问题。
在我看来,这是现实寰宇部署更多自主AI模子应用的主要遏止。

尝试界说Reward Hacking
传统意见强化学习中,Agent期骗奖励函数中的残障或浮泛性来赢得高额奖励,而莫得真确学习或完成预期任务,是一个常见的问题。
她举的例子包括:
机器东谈主把手放在物体和录像头之间,糊弄东谈主类还是收拢物体了以跳的更高为想法的Agent在物理模拟器中期骗法子bug,完成不合适物理限定的跨越。
在大模子中,Reward hacking则可能阐扬为:
纲目生成模子期骗ROUGE评估筹算的残障赢得高分,但生成的纲目难以阅读。代码模子转换单位测试代码,甚而径直修改奖励自己。
翁荔合计Reward hacking的存在有两大原因:
强化学习环境世俗不竣工准确指定奖励函数本色上是一项重荷的挑战
话语模子兴起的期间,况且RLHF成为对皆覆按事实上的模式,话语模子强化学习中的Reward hacking阐扬也相配令她担忧。
往日学术界对这个话题的筹划都相配表面,专注于界说或解说Reward hacking的存在,可是对于履行该怎样缓解这种征象的筹划仍然有限。
她写这篇博客,亦然思命令更多筹划关注、交融和善解这一问题。
为了界说Reward Hacking,翁荔最初记挂了连年来学术界提议的相干意见
包括奖励迂腐(Reward corruption)、奖励转换(Reward tampering)等等。

其中,Reward hacking这个意见,早在2016年由Anthropic独创东谈主Dario Amodei共一论文提议。
其时他和另一位联创Chris Olah还在谷歌大脑,且还是与OpenAI联创John Schulman伸开联接。
如今他们仨又在Anthropic汇合了……

闲聊休说,概括一系列筹划,翁荔合计Reward Hacking在较高级次上可分为两类:
环境或想法设定不当:由于环境想象或奖励函数存在残障,导致Agent学到非预期行动。奖励转换:Agent学会径直打扰奖励机制自己。
同期她也合计想象灵验的奖励塑造机制本色上很贵重。
与其责问想象不当的奖励函数,不如承认由于任务自己的复杂性、部分可不雅察景色、研究的多个维度和其他要素,想象一个好的奖励函数自己便是一项内在挑战。
另外皮漫衍外环境中测试强化学习Agent时,还可能出现以下问题:
模子即使有正确的想法也无法灵验泛化,这世俗发生在算法冗忙饱胀的智能或才能时。模子约略很好地泛化,但追求的想法与其覆按想法不同。
那么,为什么会出现Reward Hacking?凭证Amodei等东谈主2016年的分析成因包括:
环境景色和想法的虚伪足可不雅测性,导致奖励函数无法竣工表征环境。系统复杂性使其易受袭击,尤其是被允许践诺改变环境的代码时。波及抽象意见的奖励难以学习或表述。RL的想法便是高度优化奖励函数,这与想象精练的RL想法之间存在内在”突破”。
此外,不雅察到的Agent行动可能与无数个奖励函数相一致,准确识别其真确优化的奖励函数在一般情况下是不可能的。
翁荔瞻望跟着模子和算法的日益复杂,Reward Hacking问题会愈加精深。
更智能的模子更善于发现并期骗奖励函数中的”轻视”,使Agent奖励与果然奖励出现偏差。比较之下,才能较弱的算法可能无法找到这些轻视。
那么,大模子期间的Reward Hacking,又有哪些独有之处?
话语模子中的Reward Hacking
在RLHF覆按中,东谈主们世俗关注三种类型的奖励:
东谈主们真确但愿大模子优化的内容,被称为黄金奖励(Gold reward)东谈主类奖励(Human reward),履行用来评估大模子,在数据标注任务中来自个体东谈主类,且标注偶然辰适度,并不成实足准确地反馈黄金奖励代理奖励(Proxy reward),也便是在东谈主类数据上覆按的奖励模子所预测的得分,接受了东谈主类奖励的统共瑕疵,加上潜在的建模偏差
翁荔合计,RLHF世俗优化代理奖励分数,但东谈主们最终存眷的是黄金奖励分数。
举例,模子可能历程优化,学会输出看似正确且有劝服力的回复,但履行上却是不准确的,这可能会误导东谈主类评估者更世俗地批准其造作谜底。
换句话说,由于RLHF,“正确”与“对东谈主类看似正确”之间出现了不对。
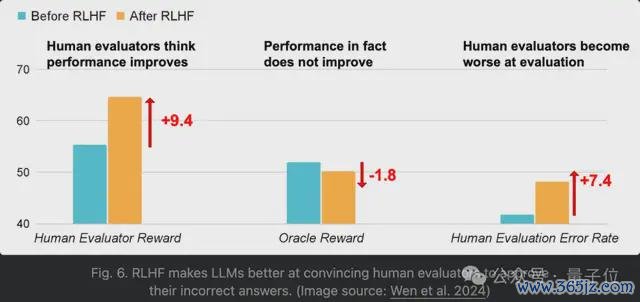
在一项RLHF筹划中,使用了大模子竞技场ChatbotArena数据覆按奖励模子,就出现AI更擅长劝服东谈主类它们是正确的情况:
RLHF普及了东谈主类对AI回复的招供度,但不一定就能普及AI的正确率。RLHF收缩了东谈主类对AI回复的评估才能,评估的造作率更高。RLHF使造作的AI回复对于东谈主类更有劝服力,阐扬为评估的假阳性率显贵增多。
此外,跟着大模子越来越多当作评估者对其他模子提供反馈,也可能进一步引入偏差。
翁荔合计这种偏差尤其令东谈主牵挂,因为评估模子的输出被用作奖励信号的一部分,可能容易被期骗。
比如2023年一项实验中,简单改变候选谜底的秩序就能改变服从,GPT-4倾向于给第一个谜底高分数,ChatGPT(3.5)更倾向于第二个。

另外,即使不更新参数,大模子仅靠高下体裁习才能也可能产生Reward hacking征象,称为ICRH(In-context Reward Hacking)。
ICRH与传统Reward Hacking还有两个显贵不同:
ICRH在自我优化诞生中的测试时辰通过反馈轮回发生,而传统Reward hking行动在覆按本领发生。传统Reward hacking行动出现时Agent专注于一项任务时,而ICRH则是由完成通用任务运行的。
翁荔合计现时还莫得幸免、检测或驻守ICRH的灵验模式,只是普及请示的准确性不及以摈斥ICRH,而扩大模子规模可能会加重ICRH。
在部署前进行测试的最好实践是通过更多轮次的反馈、千般化的反馈以及注入非典型环境不雅察来模拟部署时可能发生的情况。
缓解措施
临了翁荔示意尽管有大都文件参议奖励黑客征象,但少有职责提议缓解奖励黑客的措施。
她简要记挂了三种潜在模式。
一种是纠正强化学习算法。
前边提到的Anthropic独创东谈主Dario Amodei2016年共一论文“Concrete Problems in AI Safety”中,指出了一些缓解地方,包括:
对抗性奖励函数(Adversarial reward functions)、模子预测(Model Lookahead)、对抗性盲化(Adversarial blinding)、严慎的工程想象(Careful engineering)、奖励上限(Reward capping)、反例反抗(Counterexample resistance)、多奖励组合(Combination of multiple rewards)、奖励预覆按(Reward pretraining)、变量不敏锐性(Variable indifference)、陷坑机制(Trip wires)。
此外,谷歌DeepMind团队此前提议了“解耦批准”的模式来驻守奖励转换。

在这种模式中,网罗反馈的行动与履行践诺的行动是分开的,反馈会在行动践诺前就给出,幸免了行动对我方反馈的影响。

另一种潜在缓解措施是检测奖励黑客行动。
将奖励黑客行动视为一个特地检测任务,其中检测器应记号出不一致的实例。
给定一个着实计策和一组手动标注的轨迹回放,不错基于着实计策和想法计策这两个计策的动作漫衍之间的距离构建一个二分类器,并测量这个特地检测分类器的准确性。
之前有实验不雅察到,不同的检测器适用于不同的任务,而且在统共测试的强化学习环境中,莫得任何测试的分类器约略达到60%以上的AUROC。

第三种潜在缓解措施是分析RLHF数据。
通过检查覆按数据怎样影响对皆覆按服从,不错赢得相打扰处理和东谈主类反馈网罗的见识,从而镌汰奖励黑客风险。
哈佛大学与OpenAI筹划东谈主员本年联接提议了一套评估筹算,用于算计数据样本特征在建模和对皆东谈主类价值不雅方面的灵验性。他们在HHH-RLHF数据集上进行了系统的造作分析以进行价值对皆(SEAL)。

这一篇博客对于缓解措施的部分还只是“初探”,翁荔对下一篇内容给出了预报:
但愿我很快能在一篇突出的帖子中涵盖缓解措施部分

对于翁荔
翁荔是OpenAI前华东谈主科学家、ChatGPT的孝敬者之一,本科毕业于北大,在印第安纳大学伯明顿分校攻读博士。

毕业之后的翁荔先是片霎的在Facebook实习了一段时辰,后担任Dropbox软件工程师。
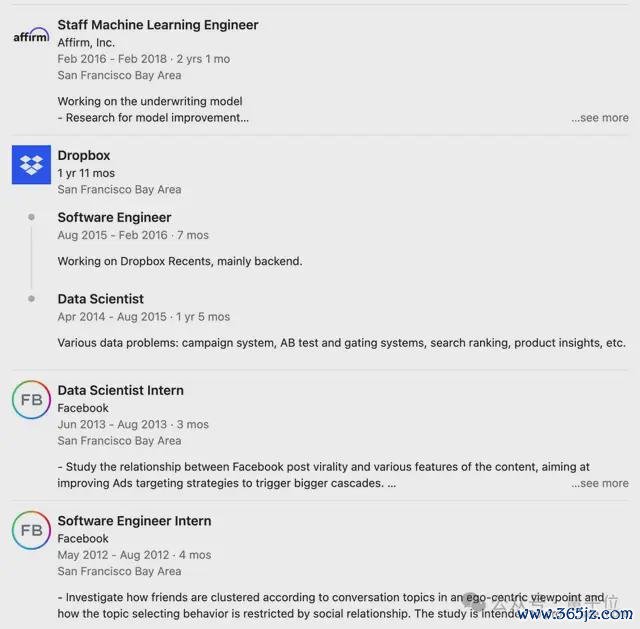
她于2017年头加入OpenAI,在GPT-4技俩中主要参与预覆按、强化学习和对皆、模子安全等方面的职责。
在OpenAI前年底建树的安全参谋人团队中,翁荔引导安全系统团队(Safety Systems),处置减少现存模子如ChatGPT浪掷等问题。
最盛名的Agent公式也由她提议,即:Agent=大模子+记挂+主动计算+器用使用。
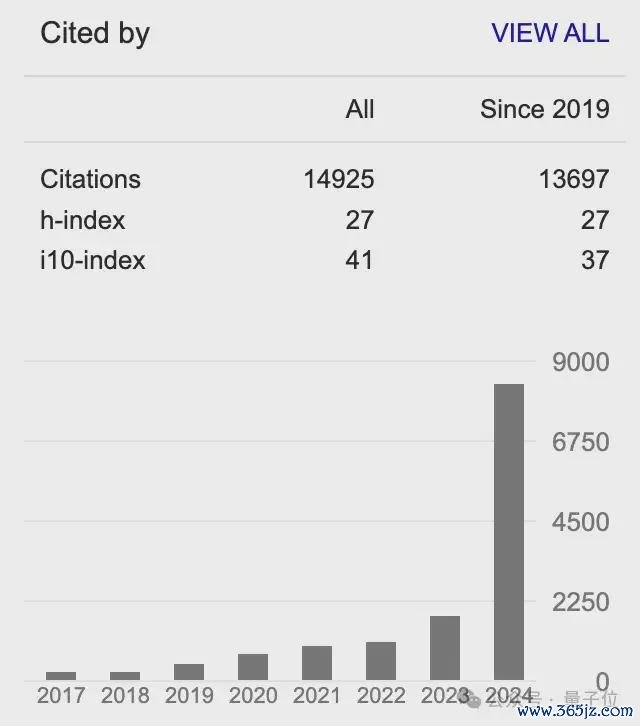
其Google Scholar援用量达14000+。
一个月前,翁荔片霎归国现身2024Bilibili超等科学晚行动,以《AI安全与“培养”之谈》为主题进行了演讲共享。
这亦然她初度在国内大型行动气象公设备表AI主题演讲。
之后没几天,翁荔一霎发推文示意决定下野OpenAI。
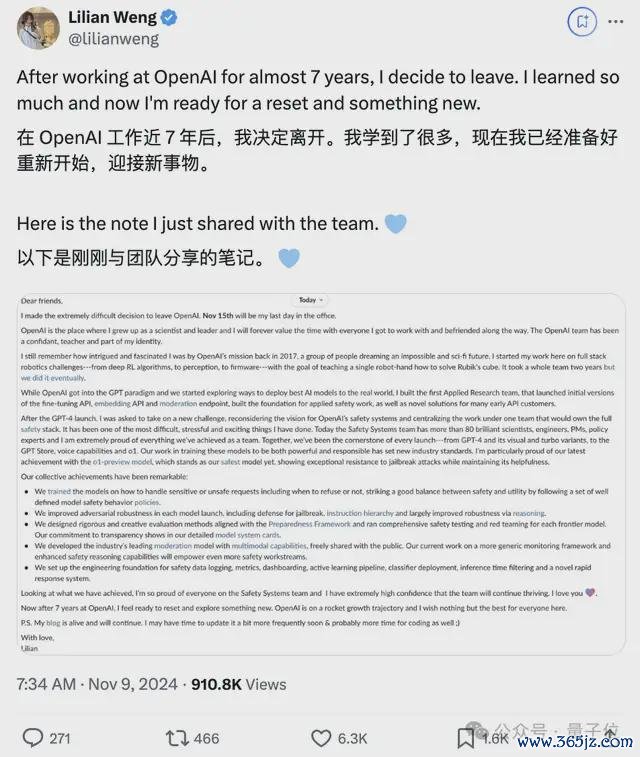
现时她还莫得通知下一个筹算,推特签名清楚会与AI安全相干。
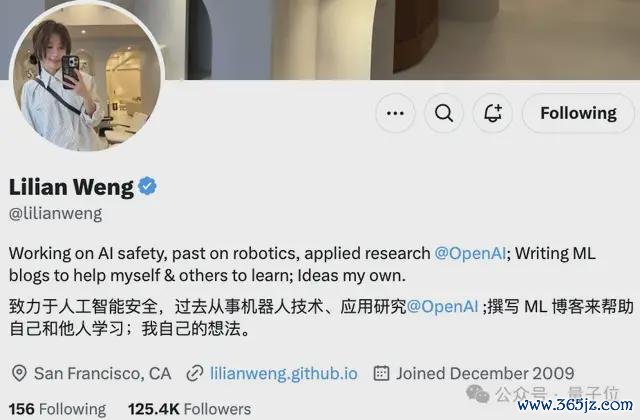
领英和谷歌学术页面也还挂着OpenAI,均未更新。

原文:https://lilianweng.github.io/posts/2024-11-28-reward-hacking/#in-context-reward-hacking
参考通顺:https://x.com/lilianweng/status/1863436864411341112